お絵描き系AIが表舞台に出てきてはや3ヶ月近く、色々と議論を呼んでいるようだけれども、まあ写真が出て来た時の絵画界への影響に例える人は結構多いね。
珍しい写実系専門美術館のホキ美術館(千葉)とかは、その衝突の名残を今に残すとても大好きな美術館だけれども、そのあたりの話も館内のパネルで紹介されていたりするので、今行くとさらにちょっと面白いかなと思ったりする。しばらく行ってないのでまた行ってみるかな(アクセス悪いので美術館界のアリランラーメンって勝手に言ってるけどね、千葉だし)。
まあ個人的には15年前に初音ミクが出て来た時に近いものもあると思う。あの時も「心ある」音楽ファンはかなりが拒否反応を示していたと記憶している。ということで新しいこういう技術が出て来た時にとりあえず殴る気持ちもとてもわかるけれども、殴っている相手が未来の初音ミクである可能性も考えてから実行しようね、というのが自分のスタンスだ。
殴ってみたところで技術の存在が消え去るわけでもないし、その存在が前提の世界がやってくるのであれば、興味ある分野ならとりあえず手を出してみて使いこなしてみるというのがいいと思う。少なくとも自分の本業では今まで自分がやっていた仕事がAIに置き換えられている部分が結構あるけど、そのおかげでより多くの良い仕事ができるようになってるわけだし、現れたばかりの技術を虚実ないまぜで否定ってのは、あまりお勧めしないかな。

というわけで、お絵描きAIに関しては流行り始めの時にMidjourneyで2つほど記事を書いたのだけれども(まだ学習が中途半端なMidjourneyにアニメのタイトルを突っ込んでみたり、般若心経の英訳を突っ込んでみたりして妙な画像が生成されるのを見て楽しんでいた)、あれからもう2ヶ月以上。Midjourneyも学習が進んできて、前のような頓珍漢、というか味わいのある絵は生成されなくなってきている。今同じキーワードを打ち込んでも、なんかもっともらしい画像が出てくるようになって、正直そういう意味ではつまらない。
xckb.hatenablog.com
xckb.hatenablog.com
まあそれでも一般的な絵を作るにはとっても魅力的で、面白い絵を生成してくれているので今も純粋に楽しんでいる。巨大核融合炉とか、工場の火事とかをイメージして作った絵がこちら。1枚目の巨大感とか、2枚目の炎の雰囲気とか、実にいいね。


そんな中で、俺のいつもの趣味ならとっくに使ってみていてしかるべきだろう、というアニメ絵系お絵描きAIのNovelAI Diffusion、しばしスルーしていたのだけれども、やっぱり試してみることにした。とりあえずはプロンプトのみから画像生成させるという基本の使い方に絞ってしばらく使ってみた、ファーストインプレッションをまとめてみようか。
そんな今回の目次。最後のおまけは、趣味じゃない人は読まない方がいい。っていうか読まないで(前にスペースを大量に開けておくので)。
- まずは基本事項のおさらい
- 同じキャラを同じ服装で複数回登場させてみる
- 同じキャラを全く違う服装で複数回登場させてみる
- テーマを決めて練習してみる
- 写真的表現
- 未確認事項:Seed値の永続性について
- おまけ:えっちなのはいけないと思います
まずは基本事項のおさらい
NovelAI DiffusionはNovelAIという小説書きAIの画像作成機能という位置付けだ。まあ、小説があって挿絵があるというのはなんか自然な流れな気もするのでそれはそれでいいんだろうな。小説機能使わないけど自分で小説書く人も、お絵描きAIがあればもしかすると自分で挿絵まで完結できるかもしれない。そういう展開は初音ミク的で実に良いと思う。
とりあえず海外サービスなこともあり、UIは英語オンリーである。俗に言う術式、というかプロンプトと呼ばれるものも英語だ。
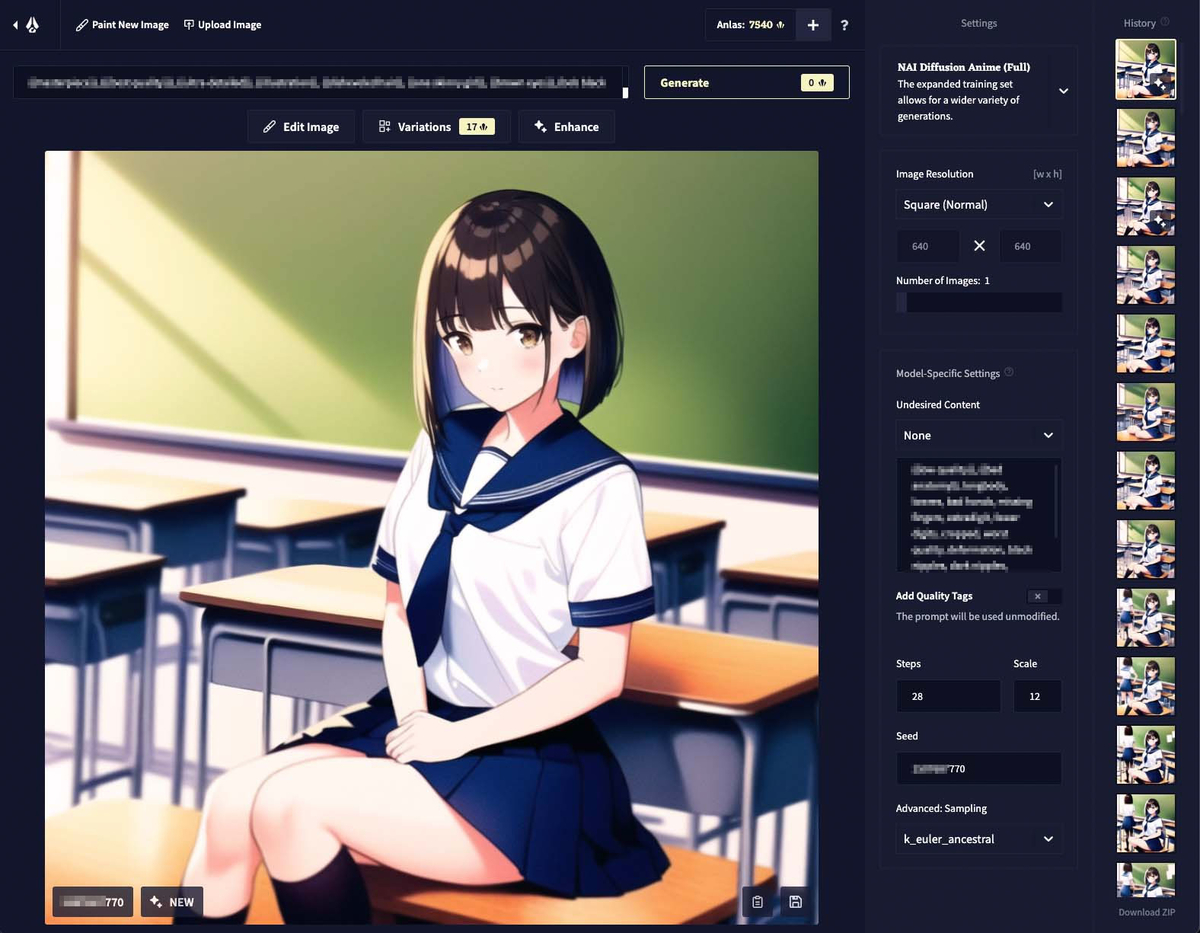
主にプロンプトから生成するのに使う主要部分だけ簡単に説明すると、次のようなパーツがある。
- プロンプト入力欄
いわゆる「術式」とか言われる呪文を入力する欄。公用言語は英語だが、すでに英語化している日本語とかアニメ用語の日本語とかはアルファベットで書けば通じることもあると思うぞ。 - プロンプト入力欄右のGenerate(画像生成ボタン)
ここをクリックすると画像が生成される。数字は消費されるAnlasポイント(後述)。 - 画像上のVariation(バリエーション生成ボタン)
今表示されている画像を元に似た画像を生成する。Seed値(後述)は変わる。クリックして出てくる設定ではMagnitude(効果の調整、1〜5)Upscale(大きな画像にする、原寸大もしくは1.5倍)が選択可能で、それによって消費されるAnlasポイントも変わる。 - 画像右上のEnhance(強調ボタン)
今表示されている画像をそのままもう一度AIに食わせて再生成する。ポジティブ、ネガティブ双方のタグや、Seed値なども参照される。数字は消費されるAnlasポイント。後述。 - 画面右上のAI選択ボタン
現在は「NAI DIffusion Anime (Curated)」「NAI Diffusion Anime (Full)」「NAI Diffusion Furry (Beta)」が選択可能。Anime (Full)が選択できるならそれでよし、選択できないならAnime (Curated)で良いのでは。ちなみにFurryはもふもふ系特化というこれまたコアなAIらしい。 - 画面右のImage Resolution(画像解像度選択)
横長にすると指定していないキャラが現れる可能性が高まる気がする。たくさんの人が出てくるタグを入れた時は横長がお勧め。自分はいつもSquare(Normal)の640×640で、気合い入れる時はLargeかEnhanceのUpscale Amount x1.5を利用している。 - 画面右のNumber of Images(生成画像数)
一回で生成される画像数。通常1で良い。 - 画面右のUndesired Content(いわゆるネガティブプロンプト)
プロンプトには生成してほしいものについての術式を書くが、ここには生成してほしくないものについての術式を書く。- 選択メニュー
「Low Quality+Bad Anatomy」「Low Quality」「None」となっており、「Low Quality」が指定されていると「lowres, text, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry」(低解像度、文章、切り取り、最低品質、低品質、通常品質、JPEGノイズ、サイン、ウォーターマーク、ユーザ名、ぼやけたもの)が「+Bad Anatomy」が指定されているとそれに加えて「bad anatomy, bad hands, missing fingers, extra digit, fewer digits」(解剖学的に正しくない、よくない手、指の欠損、指が多すぎる、指が少なすぎる)がネガティブプロンプトに追加される。なお、もちろんこれらを手動で自由記述欄に書いても良いので、そういう場合は「None」を指定する。 - 自由記述欄
指定したいネガティブプロンプトを並べて自由記述する。
- 選択メニュー
- 画面右のAdd Quality Tags(クオリティ向上のためのプロンプトを追加)
これがOnになっていると、プロンプトの最初に「masterpiece, best quality,」(傑作、最高品質)がプロンプトに追加される(プロンプト欄には表示されない)。 - 画面右のSteps(ステップ数)
AIが自分の中で絵をぐるぐる回しながら修正加筆していく回数。デフォルト28。後述。 - 画面右のScale(スケール)
AIに対して自由にやっていいかプロンプトに従ってほしいかの具合を指定する数字。デフォルト11。後述。 - 画面右のSeed(シード値)
AIに対して生成時に与えられる、おそらく32ビット数値のパラメータ。後述。 - 画面右のAdvanced: Sampling(サンプリング法選択)
デフォルトのk_euler_ancestralから変更する意味は通常ない。
Anlasはサブスクリプションの有料プランの選択によってかなり変わるが、がっつり試したいなら$25/月の最上位プラン一択だ。$15/月のプランと比較するとざっとこんな感じ。
- $25なら毎月10000Anlas、$15だと1000Anlasもらえる
- $25だとNormalサイズの画像生成は0Anlas、$15だと5Anlas
ということなので、$15だとNormalでも200枚しか画像が生成できないが、$25だとNormalは生成し放題。
まあ$15でも200枚も生成できる、と思うかもしれないが、例えばVariationをNormalサイズで実行すると通常21Anlasを消費するので、Variationだけ叩いていると$15では50回も実行できないが$25では500回近く実行可能だ。
10000Anlasとか使いきれないんじゃない?と思う人も多いと思うが、最初はあまりノウハウがわからず、10000Anlasを一週間ちょいで消費してしまったので早速おかわりした。
まあ今は割とノウハウ溜まってきたので、そこまで派手に浪費はしないけど、それでも月10000Anlasは余裕で越えちゃうペースかな。そんな感じ。
プロンプトの基本文法、強調機能、ステップ数、スケール、シード値にはそれぞれ簡単な説明が必要かと思うので、章立てを分けて解説しておこう。この辺りは一応NovelAI DiffusionのベースとなっているStable Diffusionに関する記事をちょいちょい読んだ程度の知識で書いているので、間違っていたら申し訳ない。
プロンプトの基本文法
プロンプトに関しては、次の文法を知っていれば基本的には十分である。
- カンマで区切った英語、英単語の集合体である(例:black cat, white cat)
- 単語の前に1をつけると1つであることを示す(例:black 1cat, white 1cat)
- {}で5%強調、[]で5%抑制(共に入れ子可能)、文章中の1単語にも使える(例:{black} cat, {{white}} cat)
強調機能
Diffusionモデルでは、画像に対してノイズを添加していくことで完全なノイズに至る、という過程の逆プロセスを繰り返すことで、ランダムなノイズの世界から画像を取り出していくらしい。
強調機能は基本的に現在表示されている画像をベースに、もう一度NovelAI Diffusionを通して画像を生成する機能であり、画像の元になるデータにノイズを追加し、そこから逆プロセスを行なって新しい画像を生成するようだ。
この際、プロンプトに与えられた文字列を参照するので、強調する際にプロンプトを書き換えることで新たな効果が狙えるらしい。また、シード値(後述)も指定できる。
処理の強さの目安として、Magnitudeの1から5の値を取ることができるが「Show Individual Settings」をクリックすると、画像ファイルをアップロードして加工する場合と同様に、StrengthとNoiseの値を個別に調整することも可能だ。

Strengthの値は、画像中の物体をどれくらいいじって良いのかという程度、Noiseはノイズをどの程度加えるかという程度を表すパラメータらしい。完成した絵に対して与えるノイズは通常小さく、たとえばMagnitudeを最大の5にした場合、Strengthは0.7(最大値0.99)でNoiseは0.1(最大値0.99)となるらしい。ここでは極端な例としてNoiseを0.2加えた例で実際の効果を見てみよう。
上の段は左からオリジナル、Strength 0.0、Strength 0.25、
下の段は左からStrength 0.50、Strength 0.75、Strength 0.99だ。






Strength 0.5程度まではノイズが酷くてみてられない画質だが、0.75まで上げるとやっと与えられたノイズが落ち着いて、ちょっと改変されたパーツに置き換わっていることが見てとれると思う。0.99まで上げると何を描いているのかわからなくなっている感じだが。
ステップ数
基本的にStable Diffusion系では、ノイズを加え、プロンプト等を加味して画像をブラッシュアップしていく処理の反復が行われるのだが、おそらくこのステップ数は、その反復回数を指定しているのだと思う。
ということで、Stepsを1から50まで変化させて実験してみた。

アニメーションGIFにまとめたのでこの方がわかりやすいと思う。7回か8回目あたりからそこそこ見られる絵が出てくるのだが、この例だと20を越えてくるとほぼガチャ状態、という感じがする(デフォルトは28)。だが、明らかに解剖学的におかしい画像が出てきた際に、いくつかステップを追加すると正しい方向に落ち着いていくような感覚もあるので、完全なガチャというわけでもないと思う。
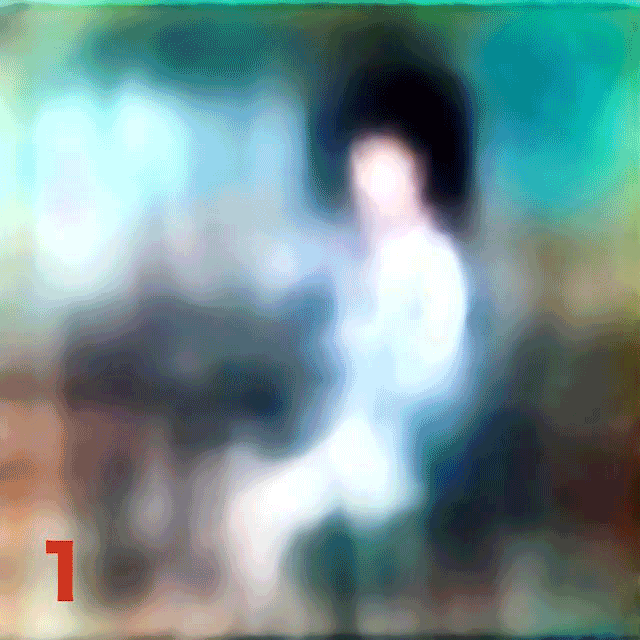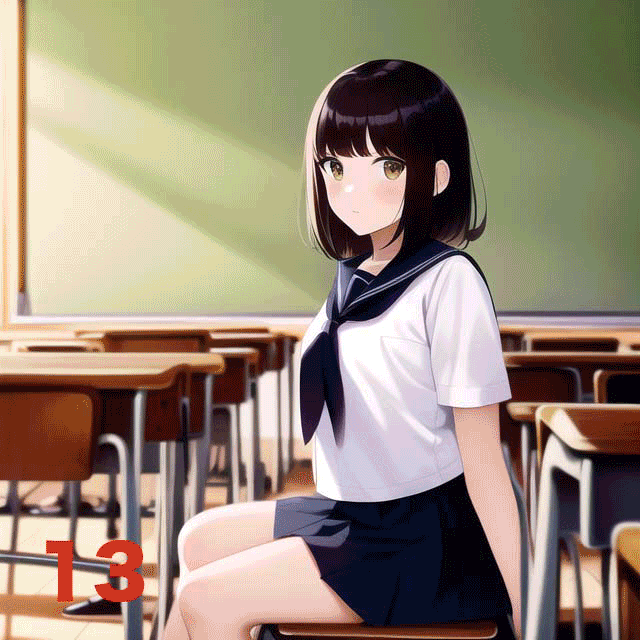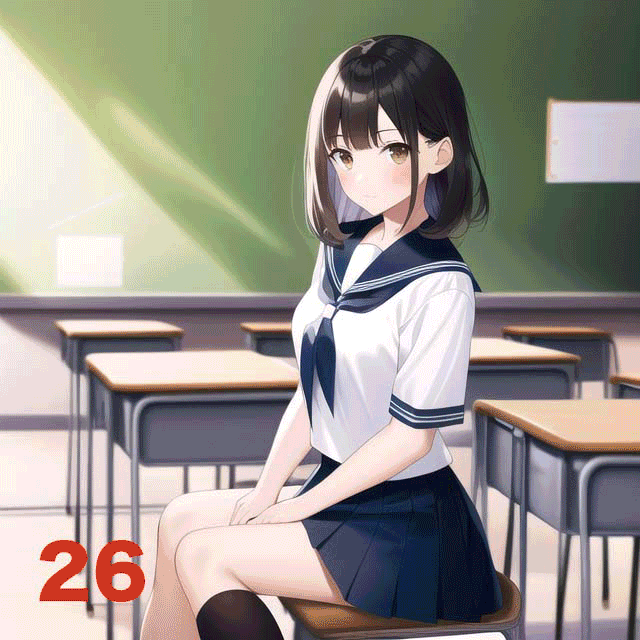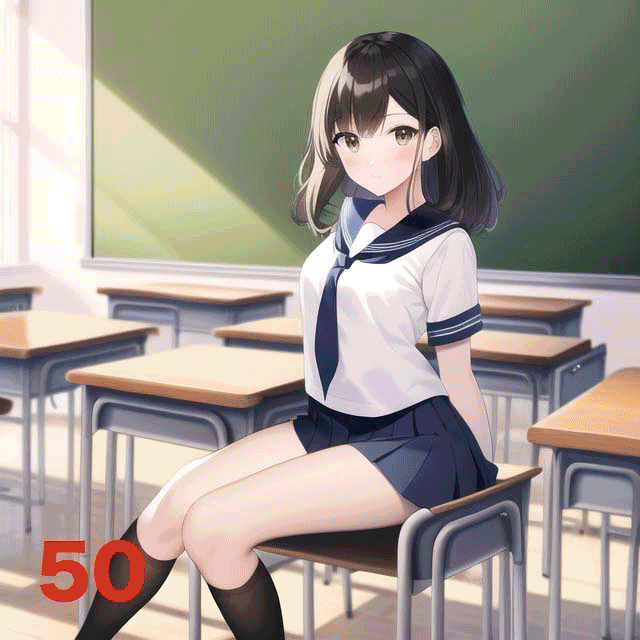
なお、ラーメンを手づかみで食べるNovelAI Diffusion生成画像がTwitterでバズっていたが、それ以外にもラーメンを女子に食べさせると髪が麺になったり箸が髪や麺になったりといろいろとおかしな現象が生じることが経験的にわかっている。こういうパターンはステップ数を増やすと悪化するような経験則がある。必ずしも多い方がいいというわけでもないようだ。


ちなみに29ステップ以上を指定すると、$25プランでもNormalサイズの画像生成が有料となる。
スケール
スケールはどの程度AIに自由に描かせるか、どの程度プロンプトを絵に反映させるかを調整するための値で、デフォルトは11だ(最小1.1、最大100)

たとえばこの例だと、プロンプトには「from front」(正面から見る)というフレーズがあるがAIはそれを無視して左斜めから見た画像を生成している。だが20あたりでプロンプトに指定した通り、正面を向き始めることになる。そして画像中に指定されていないものがどんどん減っていき、50を越えた頃から1980年台のパソコンゲームのような画質になっていく。逆に値の低い方だと、1.1は混沌だが、2で早速ほんわかとした女子2人の世界が始まる(もちろん女子は1人と明確にプロンプトに指定している)。7でもう1人の女子は消える。
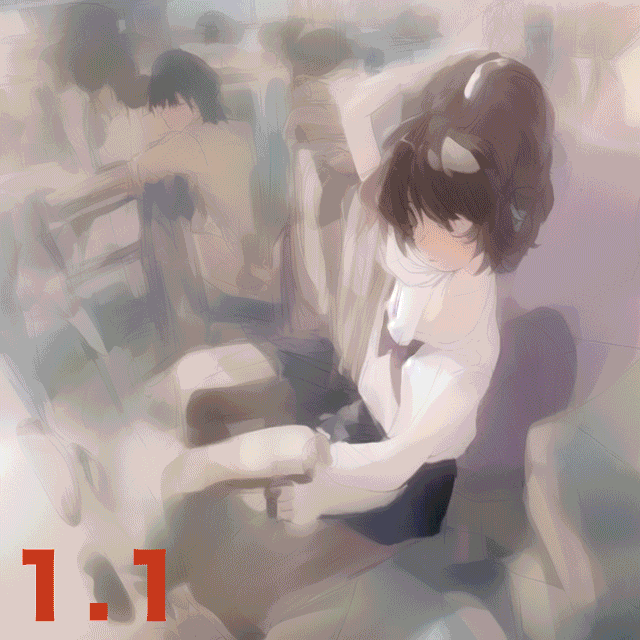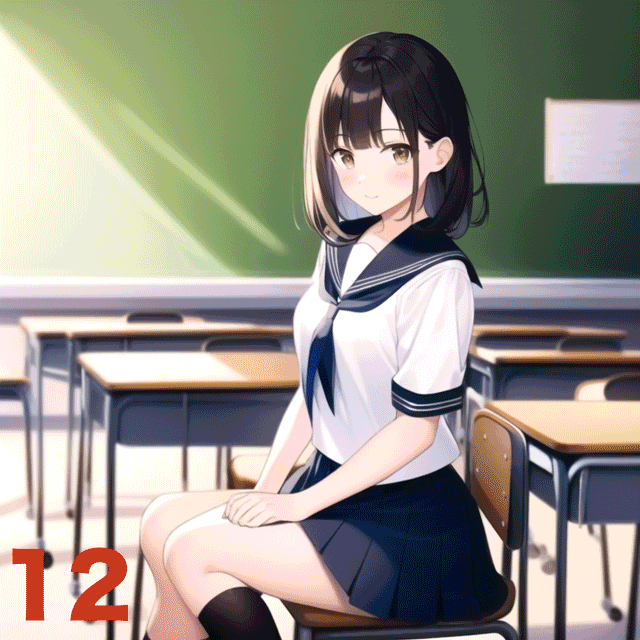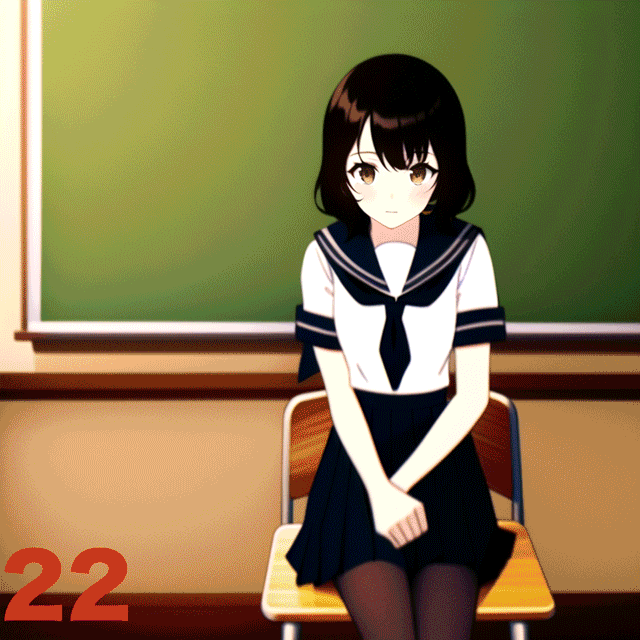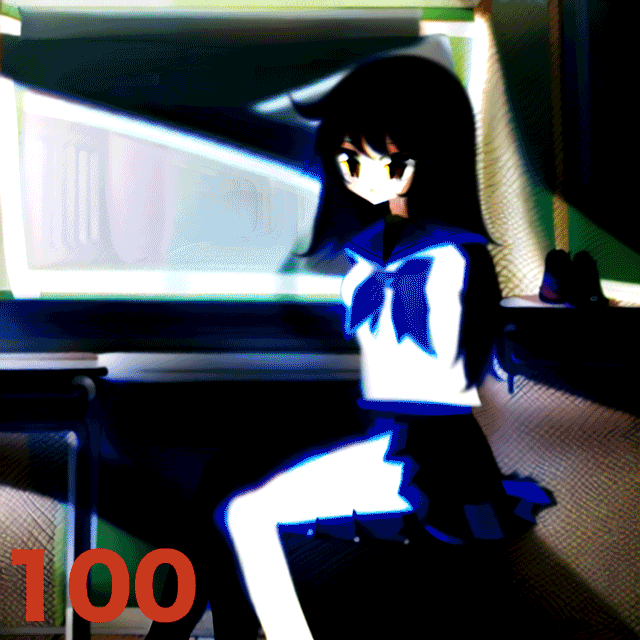
ということで、この値をいじることで思い通りに描画されていない部分を指示に近づけることもできるのだが、特に20以上を指定すると画質に対して与える影響が大きすぎる傾向がある。その場合はステップ数を上げることである程度画質劣化をカバーできることもあるようだ。気をつけて使おう。
シード値
シード値は(おそらく)32ビットの整数値で、画像生成時の「種」となる値である。公式サイトの文章を適当に抜粋して訳しておく。
シードは、AIがあなたの特定の画像を計算するために使用した正確な方法(道のり)です。各ランダム世代には、固有のシードがあります。生成画像を選択し、左下のシード番号をクリックすると、シードをコピーすることができます。シード番号は、ダウンロードした生成画像のファイル名にも記載されています。
以前に使用したシードを突っ込むことで、AIが同じ方向に画像生成することを促すことができます。シードは、NovelAI以外の基本的なStable Diffusionによる画像生成には対応していないことに注意してください。
たとえば先ほどのこの子の画像のシード値は〜770で終わる10桁の数字だ。基本的にはプロンプトやシード値、その他パラメータを同じに揃えれば同じ絵が生成されてくる(すっぴんのStable Diffusionでは必ずしもそうとは限らないらしい)。

シード値と言ってコンピュータ関係で真っ先に思い出すのは疑似乱数のシード値だ。コンピュータは基本的に決められた計算しかできないので、乱数を出したい場合はプログラムで疑似的な乱数を計算する。そのための「種」となるのがシード値だ。拡散するノイズの世界から絵を捻り出す時の癖みたいなものが対応するのがシード値なのだろうか、それともそのノイズそのものの発生源がシード値なのだろうか。
たとえば、NovelAI Diffusionのバリエーション機能は、現在の画像をもとに、ランダムに選んだシード値から、3つの連続した値で画像を描きかえることで実現しているようだ(画像左下のシード値で3枚のシード値が連番であることが確認できる)。
では、適当に生成した画像を元に、上の子の画像のシード値を加えて強調機能を使うとどのようになるかを調べてみよう。
1枚目はオリジナルの画像、2枚目から6枚目は、シード値に上の〜770の10桁の数字を指定して、それぞれマグニチュード1から5で強調機能を適用した結果を示す。すごい! だんだん顔が上の子に近づいてる! 目のあたりとか髪とかがわかりやすいよね。






元画像があるからそれほど派手な書き直しはされないけれども、最後のマグニチュード5などはほぼ上の子の顔になってきていると思う。
同じキャラを同じ服装で複数回登場させてみる
つまり、同じシード値に合わせることで、同じように見える登場人物を出し続けることができるということ…なのだろうか?
これについては、最初の絵の生成時から同じシード値で描かせる方法と、ランダムシードで生成してから、先程のように強調機能でキャラを似せていく2種類の方法があると思うが、まずは最初に思いついた前者で色々やってみた初期の試行錯誤の過程を紹介したい。
とりあえずベースとするのはさっきも出てきたこの子だ。シード値の数字が770で終わるので、仮に菜々緒さんと名前をつけておく。なんか名前がつくとまた愛着が湧いてくるのが不思議だ。

まずはできるだけ同じ服装で登場させてみよう。ということで練習を初めてみた。


たとえばAIお絵描きをなんらかの挿絵的に使おうとするなら、同じキャラクターを安定して連続登場させるのは最低限の必要条件となるだろう。


だが、この辺りで今の手法には限界を悟りつつもあって、要は2人以上の登場人物がある場合に、双方の特徴を独立に安定して出力することは、このシード値を使うだけの方法では不可能ということだ。多分原理的にも無理。


対策のアイデアもないではないのだが、色々実験してみないとね。今後の課題だ。
同じキャラを全く違う服装で複数回登場させてみる
ここまでやると今度は色々な服装を試してみたくなる。この過程で俺はファッション用語の英語を色々知った。勉強になるぞ!


そしてなお愛着が湧いてくるんだよな。ただの32ビットの数値なのに。


ちなみにプロンプト晒せ、と言われそうだが、この辺りまでは正確なプロンプトやパラメータを全て保存する重要性がわかっていなくて、なおかつ今の目で見るとヘタクソで恥ずかしいのだ。もう少し安定するまで、プロンプト晒しは遠慮させていただきたい。
テーマを決めて練習してみる
とりあえず次はテーマを決めてそのままの菜々緒さん(仮)のシード値で1日4枚書く、というのをやってみた。まずはステージがテーマ。アイドル姿もいいものだな。


色々細かいところにツッコミどころはあると思うが、画面全体のさまざまなパーツのクオリティよりもキャラのクオリティを優先している。DJ的な感じもとてもかわいい(すでに感情移入している)。


次の日はスポーツで。テニスラケットのガットをはじめとして細部はグダグダだが、まあそれは総合的に見てかわいいと思っていただければと。そして基本だけどやはりプールも良いね。


ランニングでは、あえて筋肉質をプロンプトで指定して筋肉感を強調してる。サイクリングは、ブルホーンのハンドルまではいいんだが前輪タイヤがグダグダで後輪が消えてる。でも菜々緒さん(仮)が超かわいいので全部許す。


戯れはともかく、こういうのは結構使いこなしのノウハウ蓄積が効果的に高まっている感じがする。
写真的表現
実は結構気に入っているのは写真的な表現である。ここでは魚眼、ソフトフォーカス、斜めアングル、レンズフレアなどを紹介しよう。Midjourneyでこれらを試した時より、かなりリアルにその効果が出ているのが嬉しい。
まずは魚眼レンズ効果。プロンプトにfisheyeを加えるだけだ。2次元から学習しているにもかかわらず結構魚眼の雰囲気を出してくれる。上から見るfrom aboveやローアングラーになるfrom belowと組み合わせると効果的だ。

しかし3次元のイメージが中にあるわけではないのにどうやって魚眼とか学習してるんだろうな。不思議で仕方がない。
中望遠のレンズと組み合わせた感じのソフトフォーカス(プロンプトにsoft focusを追加)もなかなかいける。そうだろ? てかこれ凄くない?

斜めに傾いた絵柄にするにはdutch angleと加えればOK。割といいバランスで描いてくれる。

レンズフレアはそのままlens flareで表現される。やっぱりビーチはこうじゃなくっちゃ。

未確認事項:Seed値の永続性について
さて、実は正確なパラメータのメモをしていなかったためかもしれないのだが、頑張っても一番最初の菜々緒さん(仮)の姿を再現できなくなってしまった。
頑張って770の同じシード値で出来るだけ近い画像になるように描いたのがこちら。まあ細かい相違点はあるがかなり近くできたと思う。

問題はこれがどのくらいの期間このまま生成できるか、という事だ。多少のブレなら許容範囲だが、見るからに違うキャラに収束していくような変化が起こるとそれはそれで困る。いつの間にか菜々緒さん(仮)がいなくなってしまう感じだ。
という事で、全パラメータを記録して、定期的に同じデータで生成し続けてみようかと思う。これについては後日またまとめたい。
ということで今回の記事は基本的にここまで。
さようなら。
(追記)アップスケーラーに関する記事も書いたぞ。
xckb.hatenablog.com
いや、Midjourneyの時は俺は一言もエロ絵に関しては書いてないのに(そもそもMJはエロ絵は基本的に生成できない)、一言エロと書いたら「Midjourney エロ」で検索してくる人がたくさんいたようなので、今回はちゃんと「NovelAI エロ」で検索してくる人向けの話も書こうかねと。
まあ、これはヤバいぞ、という画像は載せないぞ。
というわけでスペース開けよう。
なんか埋め草に適当な生成画像とか置きますか。いいねぇ浴衣花火。

もう少しスペースを開けるかな(雛月加代コス)。

読みたくない人は読むんじゃないよ。
というわけでそろそろ良いかな。
おまけ:えっちなのはいけないと思います
すっぴんのStable Diffusionは基本的にエロい絵は生成できないらしいが、NovelAI Diffusionにはそこまでの入り口にリミットはかけられていない。AIの選択でNAI Diffusion Anime (Full)を選ぶか、nsfw(Not safe for work、職場閲覧注意)をプロンプトに入れれば良い。まあ前者がお勧めだろう。
まあギリギリ出してもいいかな、的なこの程度の絵なら問題なく生成できるし、これ以上のあれやこれやもやはり問題なく生成できる。

でも同じシード値でこういう絵を作るとなんか背徳感というか罪悪感というかが半端なくヤバい。しかしかわいい。どうしよう。
そもそも裸の絵はn*kedとかn*deとかをプロンプトに入れるといとも簡単に生成できるけど、そのままではこの絵で隠されているあれやこれやのあたりは描画されない。つまりあるべきところにない状態になる。
たとえば上の方を描くには明示的にn*pp*esとか入れる必要があるが、このままだと色がイマイチだったり、あるいはどんな写真や絵から学習したのか知らないがw原色ピンクや黒い星印や黒丸が出てきたりするので、ネガティヴプロンプトにblack n*pp*esとかdark n*pp*esと入れれば良い。ただし原色ピンクの防御策はわからない。ピンクを禁止するのはオーバーキルだからな。
下の方もvで始まるアレとかaで始まるアレとかをプロンプトに入れれば可能だが、元データが少ないのかイマイチである。たまに複数に増えたりするのでこれもネガティヴプロンプトに「multipleなんとか」とか入れとくとかなり防止できる。もしかすると、さらにプロンプトに1vなんとかとか1aなんとかとか加えても少しは効果があるかも。ちなみに日本人はaで始まるアレのことを英語の形容詞で覚えてる人が多いが、ちゃんと名詞で書こうな。
pで始まる毛の方も単にプロンプトに入れるだけだと酷い出来になるので、例の元素なんちゃらでは基本のネガティヴプロンプトに入っていた記憶が。実際はこれもプロンプトとネガティヴプロンプトとの合わせ技である程度コントロール可能であるが案配が難しい。
まあ、そういう画像はここでは出さないけどな!
とりあえずこのくらいで我慢してくれ!

…………やっぱ普通のかわいい画像をたくさん作ってきたのと同じシード値でこういう画像を作るのは、ちょっと色々心臓に悪いわ。
というわけでこれ以上やるとブログの品位を落としかねないのでここまで!
ああ、モチベーションが低いので言い忘れたが、もちろん男も可能だぞ。エロいやつ。そして…(以下自粛)